
Judge Anything: MLLM as a Judge Across Any Modality
Published in KDD 2025 Datasets and Benchmarks Track, 2025
Evaluating generative foundation models on open-ended multi-modal understanding (MMU) and generation (MMG) tasks across diverse modalities (e.g., images, audio, video) poses significant challenges due to the complexity of cross-modal interactions. To this end, the idea of utilizing Multimodal LLMs (MLLMs) as automated judges has emerged, with encouraging results in assessing vision-language understanding tasks. Moving further, this paper extend MLLM-as-a-Judge across modalities to a unified manner by introducing two benchmarks, TaskAnything and JudgeAnything, to respectively evaluate the overall performance and judging capabilities of MLLMs across any-to-any modality tasks. Specifically, TaskAnything evaluates the MMU and MMG capabilities across 15 any-to-any modality categories, employing 1,500 queries curated from well-established benchmarks. Furthermore, JudgeAnything evaluates the judging capabilities of 5 advanced (e.g., GPT-4o and Gemini-1.5-Pro) from the perspectives of Pair Comparison and Score Evaluation, providing a standardized testbed that incorporates human judgments and detailed rubrics. Our extensive experiments reveal that while these MLLMs show promise in assessing MMU (i.e., achieving an average of 64.1% in Pair Comparison setting and 69.58% in Score Evaluation setting), they encounter significant challenges with MMG tasks (i.e., averaging only 50.7% in Pair Comparison setting and 47.2% in Score Evaluation setting), exposing cross-modality biases and hallucination issues. To address this, we present OmniArena, an automated platform for evaluating omni-models and multimodal reward models. Our work highlights the need for fairer evaluation protocols and stronger alignment with human preferences. The source code and dataset are publicly available HERE. 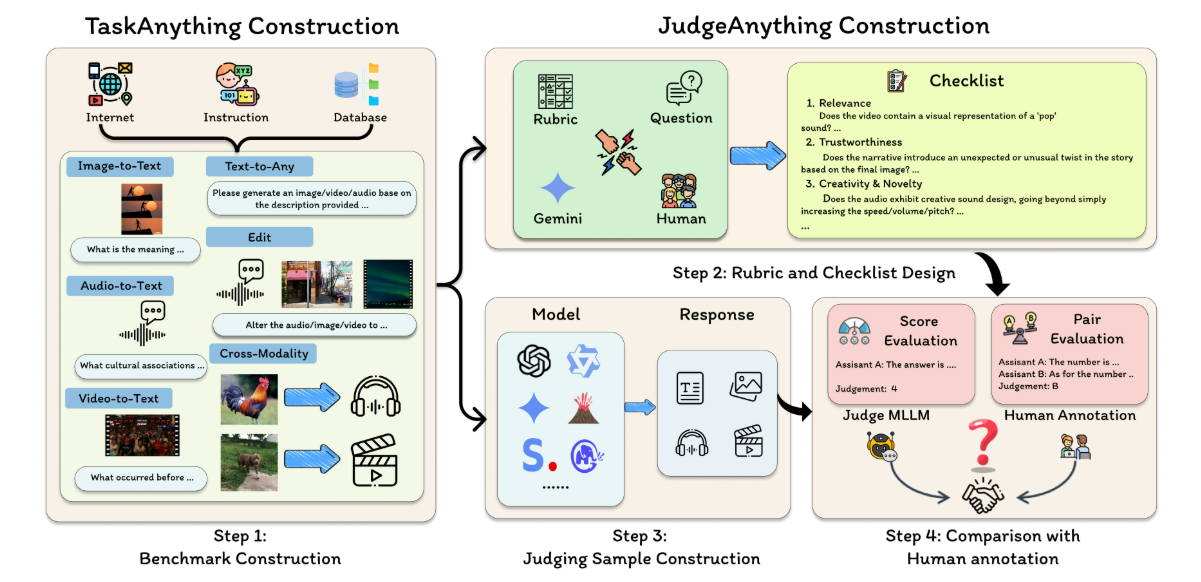
Recommended citation: @article{pu2025judge, title={Judge Anything: MLLM as a Judge Across Any Modality}, author={Pu, Shu and Wang, Yaochen and Chen, Dongping and Chen, Yuhang and Wang, Guohao and Qin, Qi and Zhang, Zhongyi and Zhang, Zhiyuan and Zhou, Zetong and Gong, Shuang and others}, journal={arXiv preprint arXiv:2503.17489}, year={2025} }
Download Paper | Download Slides | Download Bibtex